アシスタントの作成
アシスタントの作成方法
以下の方法でアシスタントを作成できます:
- 通常作成:初心者ユーザー向けで、操作が簡単かつ迅速です。
- ワークフロー作成:より複雑なビジネスロジックの設定をサポートし、上級者向けの利用シーンに適しています。
- シェアコード作成:既存のアシスタントを直接コピーし、設定を素早く再利用できます。
💡 ヒント:作成前にアシスタント作成権限をお持ちであることをご確認ください。
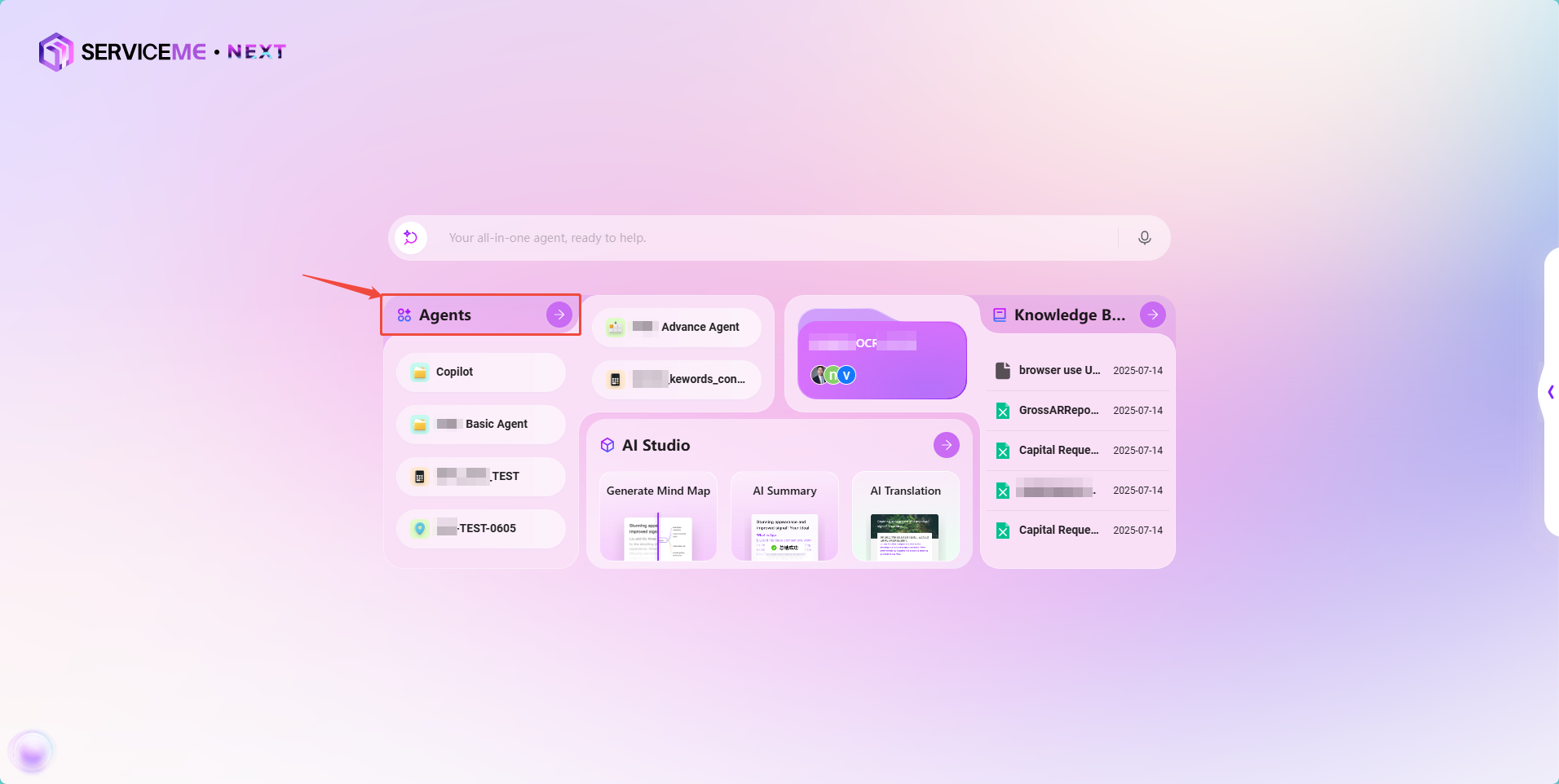
アシスタント作成のエントリーポイント(2つのショートカットエントリーどちらも利用可能)
- エントリー1:
インテリジェント体→インテリジェント体を作成
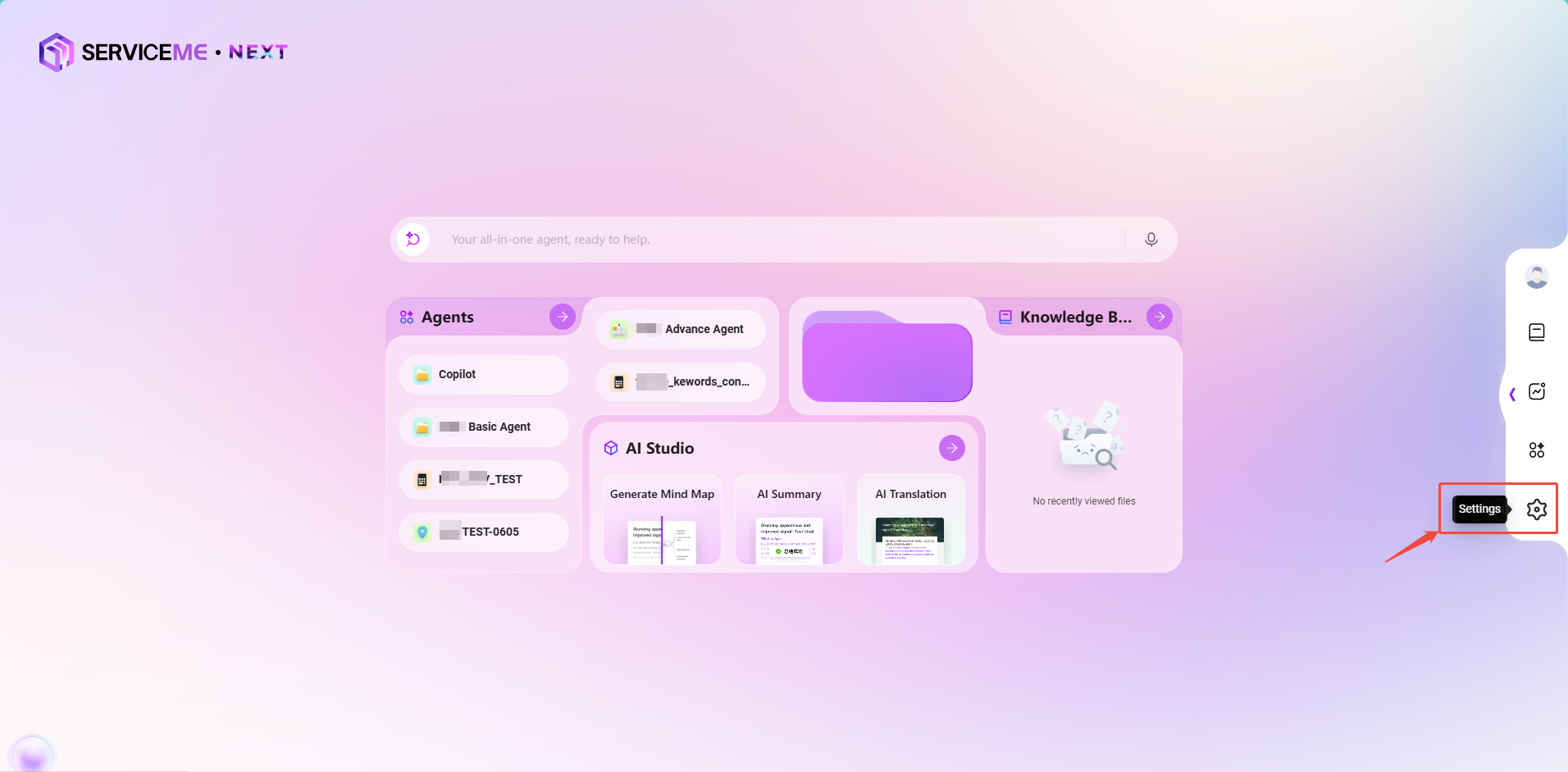
- エントリー2:
設定→アシスタント&Agent管理→インテリジェント体を作成

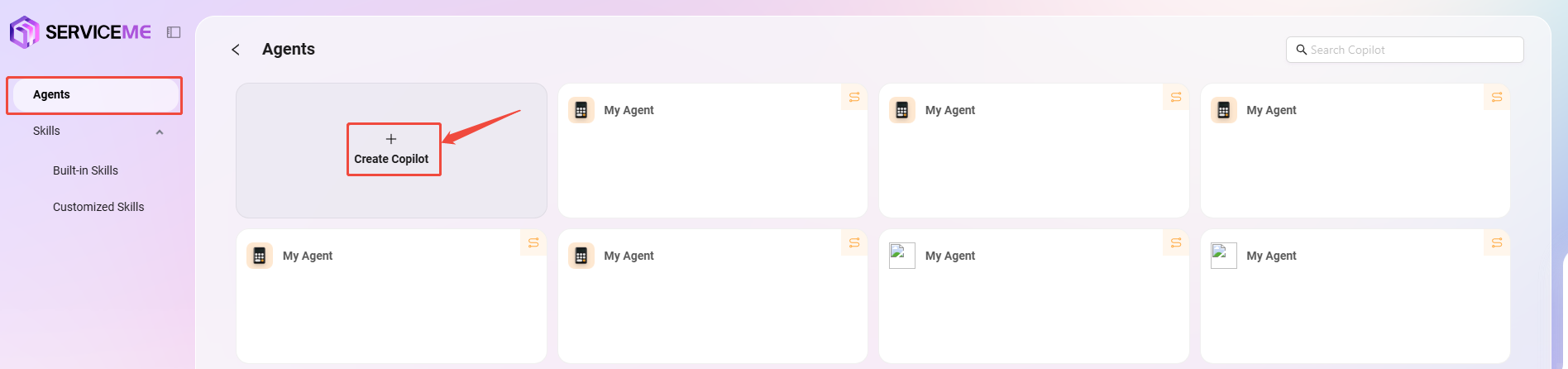
通常作成 - ベーシックインテリジェント体
1. 「ベーシックインテリジェント体」を選択
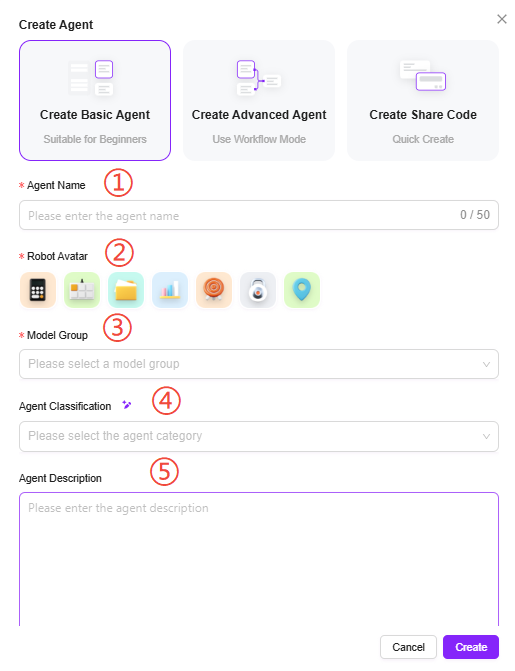
2. 作成手順
- アシスタント作成エントリーから「アシスタントを作成」をクリックし、「ベーシックオーケストレーション作成」を選択
- アシスタント名の入力、アバターの選択、モデルグループの選択、アシスタントカテゴリの選択、アシスタント説明の追加:
① アシスタント名:アシスタントの名前を入力し、識別子とします。
② アシスタントアバター:デフォルトアバターを選択します。現在アバターのアップロードはサポートされていません。
③ モデルグループ:アシスタントに適切なモデルグループを設定します。
④ アシスタント説明:簡単な説明を入力し、アシスタントの機能や用途を明記します。
⑤ アシスタントカテゴリ:新規アシスタントが所属するグループを選択します。複数選択可能です。 - 「作成」をクリックすると、アシスタント作成後にベーシックオーケストレーションアシスタント設定ページに移動し、設定・公開後に利用可能となります。
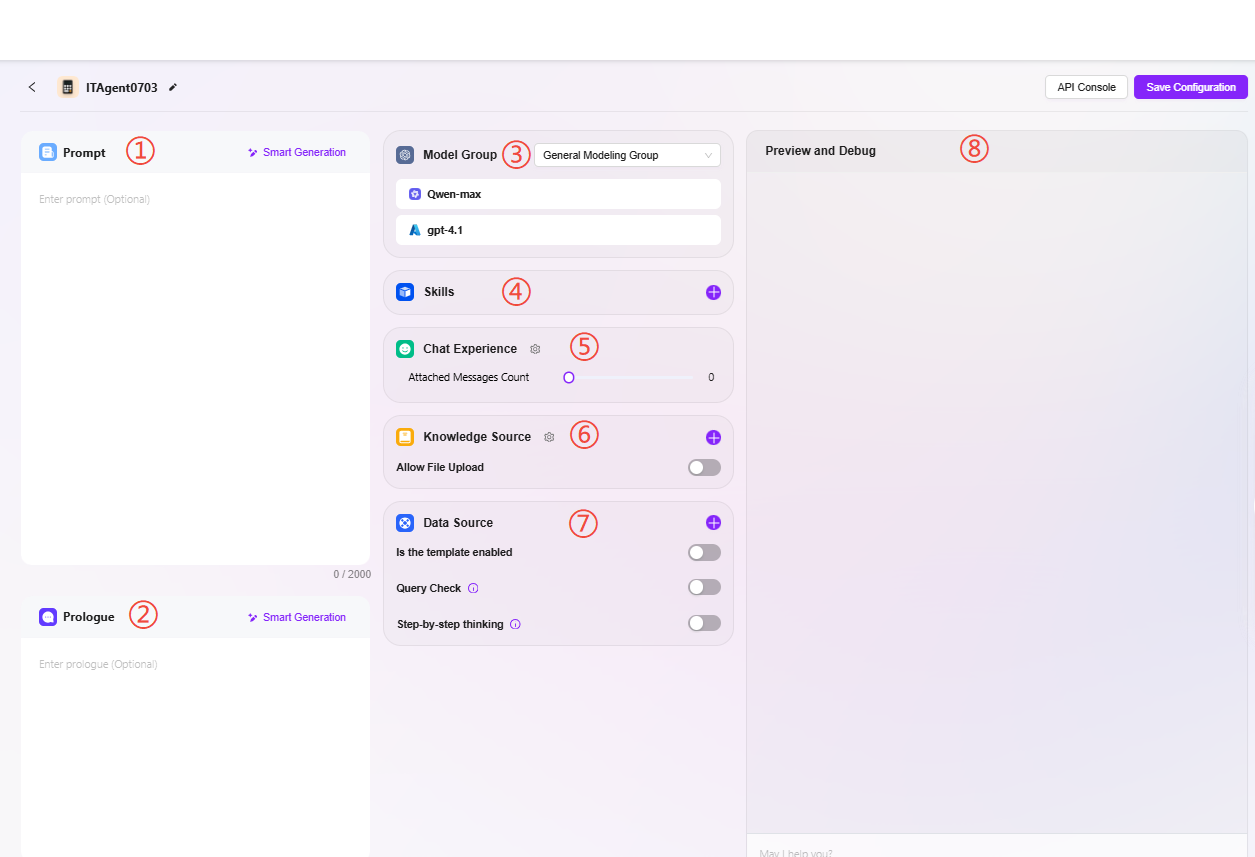
3. アシスタント設定
アシスタント設定へのアクセス方法は2通りあります:
- アシスタント作成後、直接設定ページに入る
- アシスタント名の右側「...」をクリックし、「設定」を選択
① プロンプト:アシスタントのプロンプトを入力します。既存のプロンプトからインテリジェント生成もサポート。プロンプトは最大2000文字まで
② オープニング:アシスタントのオープニングを入力します。プロンプトや既存のオープニングからインテリジェント生成もサポート。オープニングは最大2000文字まで
③ モデルグループ:「+」をクリックしてモデルグループを追加。複数のモデルが選択可能
備考:モデルグループはまず管理者がシステム管理でモデルグループを追加し、複数の異なるモデルを同じグループに追加した後、アシスタントに設定します。

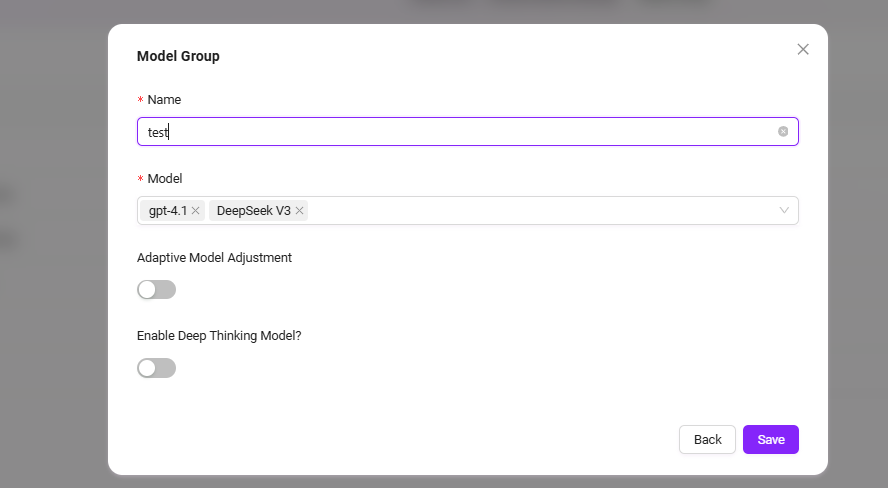
モデルグループの追加
-
パス:設定 → システム管理 → モデル管理 → モデルグループ → 新規モデルグループ(管理者のみモデル追加可能)
-
追加手順:
- 「新規モデルグループ」をクリック
- 以下の設定を完了:
- モデルグループ名を入力
- モデルグループに追加するモデルを選択(複数選択可能)
- アダプティブモデルデプロイを有効にするか選択
- ディープシンキングモデルを有効にするか選択
- 「保存」をクリック
④ スキル:「+」をクリックして1つまたは複数のスキルを追加、または推奨スキルを追加可能
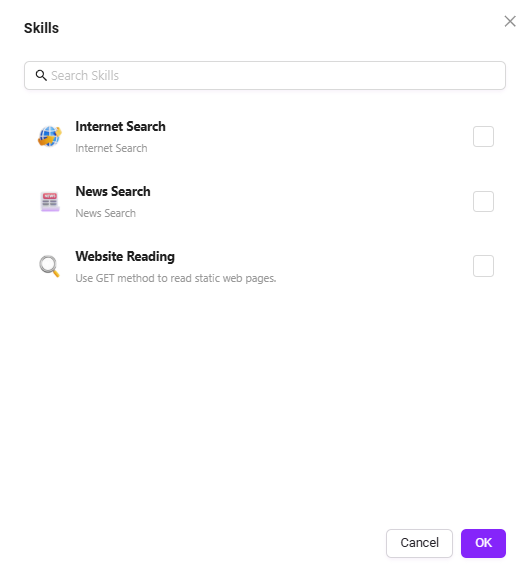
デフォルトスキルは4つあります:ウェブ検索、テキストから画像生成、ニュース検索ツール、ウェブページリーディング。
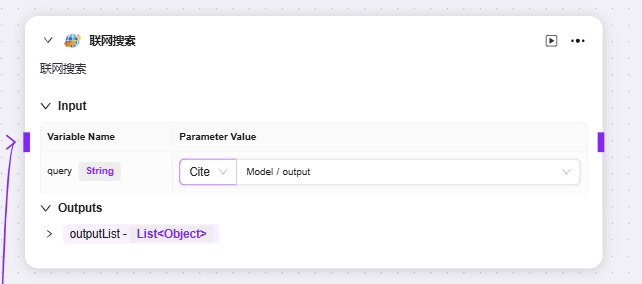
- ウェブ検索:インターネットに接続し、公開情報(ニュース、資料など)を検索する機能。
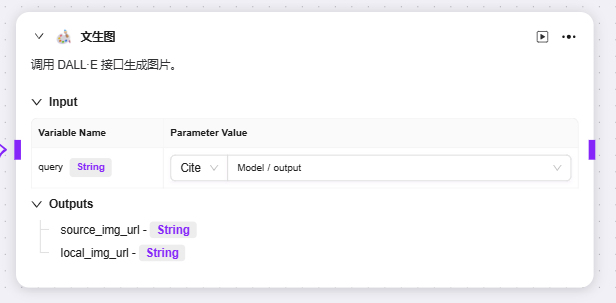
- テキストから画像生成:入力したテキスト内容からテーマに合った画像を生成する機能。
- ニュース検索ツール:各種ニュース情報の検索・取得専用ツール。
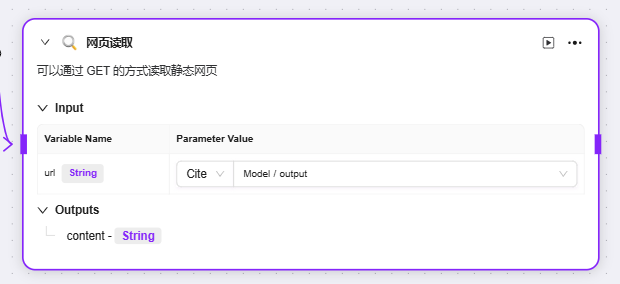
- ウェブページリーディング:ウェブページのテキストやデータなどを抽出し、情報を解析する機能。
他のスキルの追加もサポートしており、管理者による操作・設定が必要です。
⑤ 会話体験:
-
会話設定:「ユーザー質問提案」「質問ガイド」「チャット履歴」「会話フィードバック」「キーワード審査」などの設定を有効化可能
- ユーザー質問提案:アシスタントの回答後、前文に基づきユーザーに質問提案を提供します。
- 質問ガイド:ユーザーとアシスタントの会話時、関連する質問ガイドを表示し、モデルの能力でユーザーの質問や補完を推測します。
- チャット履歴:アシスタントのチャット履歴を保存するかどうか。オフにすると履歴は確認できません。
- 会話フィードバック:アシスタントの回答に対して「いいね」「バッド」などのインタラクションが可能で、回答の最適化に役立ちます。
- キーワード審査の有効化:入力内容と出力内容のいずれか一方以上を有効化する必要があります。有効化後、プロンプトやAIのフィードバック結果に対してもセンシティブワード検出を行います。センシティブワードは事前にメンテナンス可能で、以下はメンテナンスページです。
⑥ ナレッジベース:
-
ナレッジベース:「+」をクリックしてナレッジベースを追加
-
ナレッジベース設定:「検索戦略」「プライベートQA」「検索方式」など詳細設定が可能
- ファイルアップロードの許可:
1)ファイルアップロードを許可すると、ナレッジベースの内容を知識ソースとして追加できません
2)ファイルアップロードを許可しない場合、個人スペースまたは企業スペースのナレッジベースを選択的に知識ソースとして追加可能

- ナレッジベース設定:
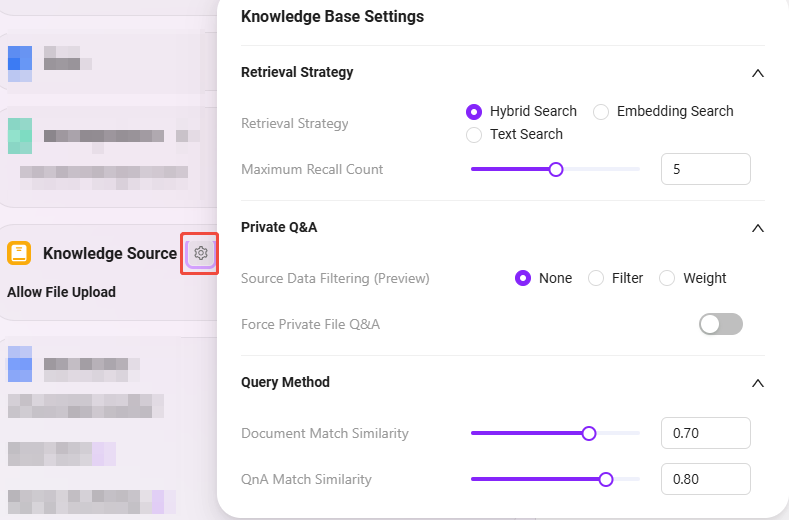
1)検索戦略:ハイブリッド検索、埋め込み検索、テキスト検索
- ハイブリッド検索:ベクトル検索と全文検索の結果を統合し、再ランキングした結果を返します
- 埋め込み検索:類似性によるフラグメント検索を行い、一定のクロスランゲージ汎化能力があります
- テキスト検索:キーワードによるフラグメント検索で、特定キーワードや名詞フラグメントの検索に適しています
2)最大リコール数:範囲 1–8。高すぎても低すぎても推奨されません。推奨値は3–5です
3)メタデータフィルタ:なし、フィルタ、重み付け
4)プライベートファイルQAの強制:有効化するとウェブ検索などのスキルは使用されず、アシスタントの回答はナレッジベース内容のみに限定されます
5)ドキュメントマッチ近似度:範囲 0–1。近似度が高いほどリコールされたドキュメント内容が類似していることを示します。推奨値は約0.8(80%)
6)QnAマッチ近似度:範囲 0–1。ドキュメント内容の近似度マッチと同様で、推奨値は約0.9(90%)
7)参考文献の表示:有効化すると、アシスタントは回答時に参考文献をリストアップし、回答の信頼性を高めます
- ファイルアップロードの許可:
💡 ヒント:最大リコール数、ドキュメントマッチ近似度、QnAマッチ近似度はいずれも高ければ良い、低ければ良いというものではありません。実際のニーズに応じて設定してください。特に要件がなければデフォルト値を推奨します。
⑦ データソース:「+」をクリックしてデータソースを追加し、アシスタントのQAデータソースとします
アシスタントのデータソースは、既に接続されているデータソースとマッチングし、アシスタントが参照できるデータソースとして利用できます。
アシスタントデータソースの追加手順は簡単です:データソースの右側「+」をクリックし、データソースを選択、「確定」をクリックするだけです。
⑧ アシスタントのプレビューとデバッグ:画面右側でアシスタントのテストプレビューができ、問題なければ設定を保存します
ワークフロー作成 - アドバンストインテリジェント体
- 「アドバンストインテリジェント体」を選択(作成手順は通常インテリジェント体と同様)
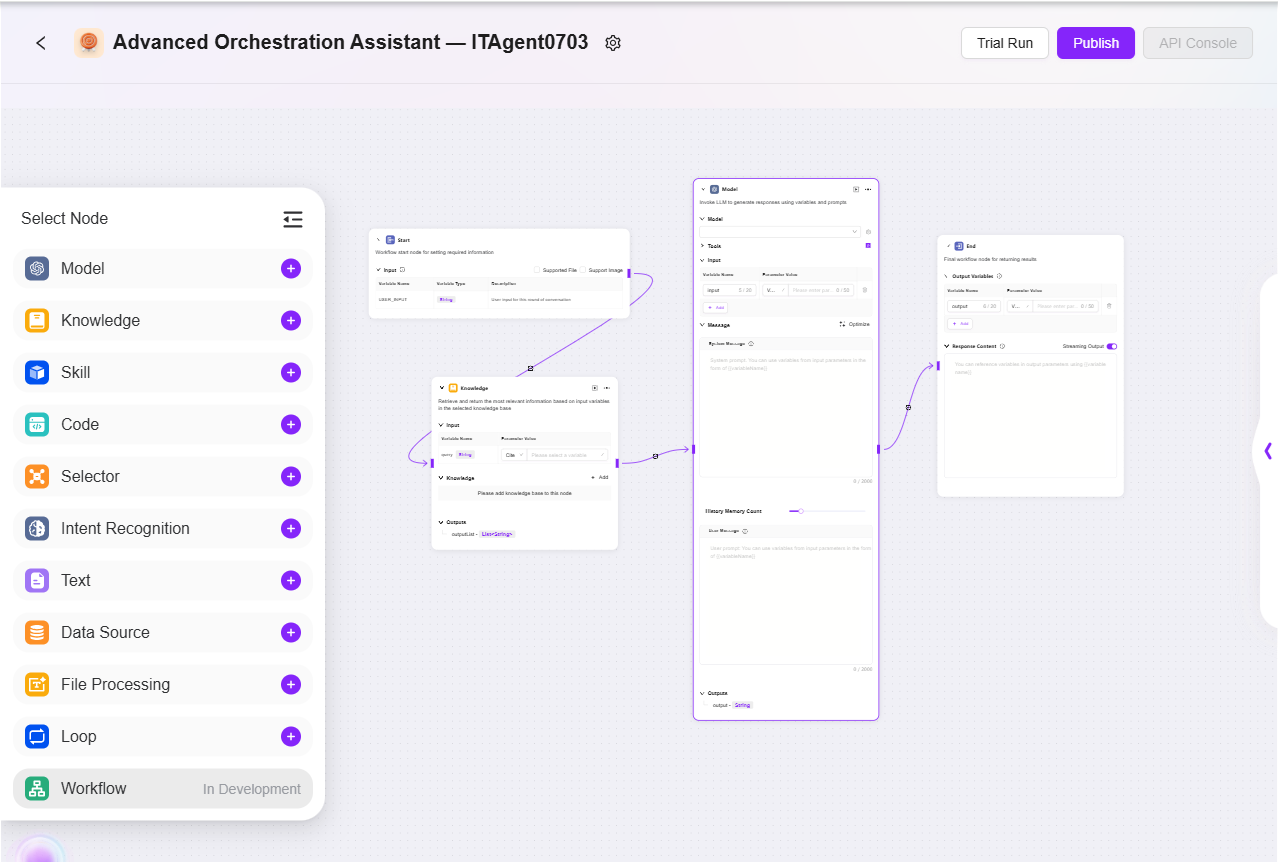
- 実際のビジネスに応じてワークフローを設定:
- 開始・終了:入力・出力モジュールが標準搭載されており、入力・出力パラメータやフィールドをカスタマイズ可能
- モデル:このモジュールで使用するモデルを選択し、他のモジュールから取得した変数を入力し、プロンプトや出力メッセージを編集し、変数として保存
- スキル:いずれかのスキルを選択し、そのスキルを通じた入出力アクションを実行
- データソース:データソースを選択し、参照可能な変数内容を増やす
- コード:他のモジュールの出力変数に基づき、コード関数のカスタム作成・編集
- ナレッジベース:選択したナレッジベース内で、入力変数に基づき最もマッチする情報をリコールし返却
- セレクター:複数の下流ブランチを接続し、条件が成立した場合のみ該当ブランチを実行。全て不成立の場合は「それ以外」ブランチのみ実行
- インテント認識:ユーザー入力のインテントを認識し、事前設定したインテントオプションとマッチング
- テキスト:複数の文字列型変数のフォーマット処理に使用
- ノード詳細説明
-
開始
-
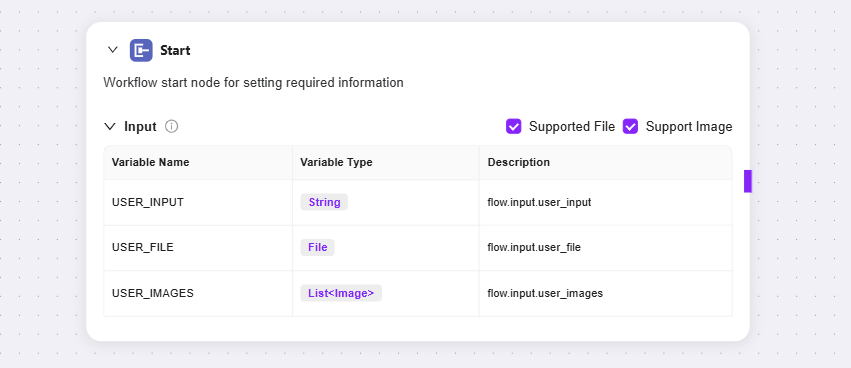
開始ノード:ワークフローの起点で、ワークフロー開始に必要な情報を設定
-
入力:LLMがタスクを完了するために必要な基本情報(入力パラメータ)を事前に伝えるイメージです。利用時、LLMはこれらの情報要件を記憶し、会話中にタスク開始のタイミングを検知すると、事前設定したパラメータを自動で該当箇所に挿入し、全体フローを開始します。
-
-
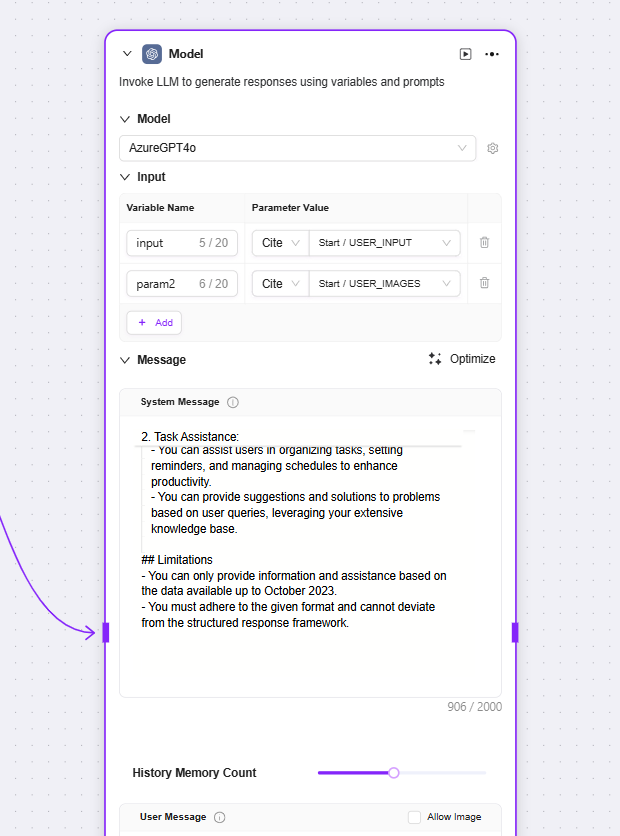
モデル
-
モデル:大規模言語モデルを呼び出し、変数やプロンプトを使って返信を生成
-
入力:既存モデルをプルダウンで選択し、入力変数名を選択
-
メッセージ:会話に高次のガイダンスを提供
-
ユーザーメッセージ:モデルに指示、クエリ、またはテキストベースの入力を提供
-
💡 ヒント:前段ノードに接続してから、他ノードの変数を現在ノードの入力変数として選択できます
-
スキル
-
現在デフォルトで3つのスキルがアドバンストオーケストレーションに追加可能:ウェブ検索、テキストから画像生成、ウェブページリーディング
-
それぞれのqueryやurlとして前段ノードの変数を入力し、対応する出力変数を取得可能
-
-
コード
-
コード:コードを記述し、入力変数を処理して返り値を生成
-
入力:外部から渡された変数を受け取るためのもので、コード実行に必要なデータの入口となり、後続のコード処理に原始データを提供
-
コード設定:コード実行に関するパラメータ(最大実行時間など)を設定し、ここでロジックを記述して入力変数を処理
-
出力:コード実行後、処理結果を指定した変数形式で出力し、コード処理結果の出口となる
-
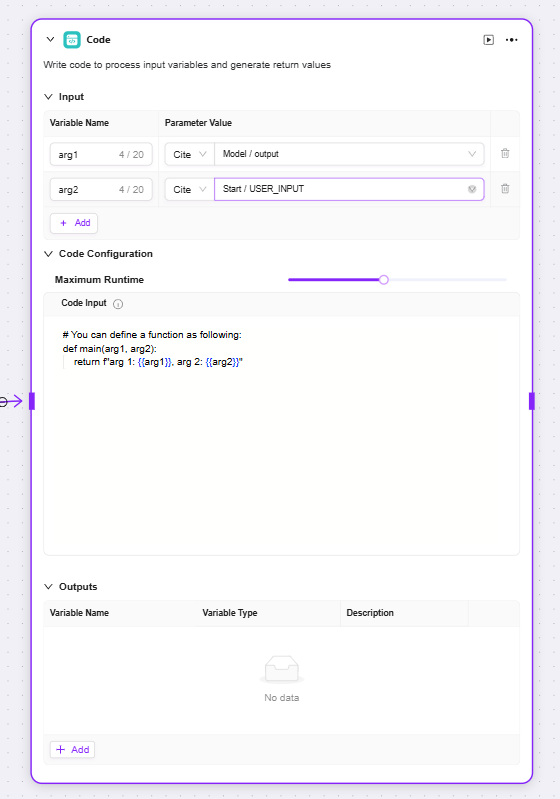
-
セレクター
-
セレクター:フローオーケストレーションで条件分岐の役割を果たします。複数の下流ブランチを接続し、設定した条件で実行パスを決定
-
条件分岐:複数の条件(例:「if - 優先度1」)を設定可能。変数参照、条件選択(等しい、大きいなどの比較ロジック)、比較値を設定し、条件成立時に該当ブランチフローを実行
-
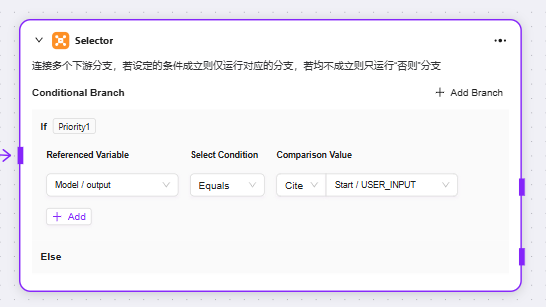
-
ナレッジベース
-
入力:変数名の定義とパラメータ値の設定により、ナレッジベース検索用のキーワードなど原始データを提供
-
ナレッジベース:特定のナレッジベースを検索範囲として選択し、その範囲内でマッチ情報を検索
-
最大リコール数:ナレッジベースから返すマッチ結果の最大数を設定し、データの過剰返却を防止
-
出力:ナレッジベースから検索したマッチ情報を指定変数形式で出力し、後続フローで利用
-
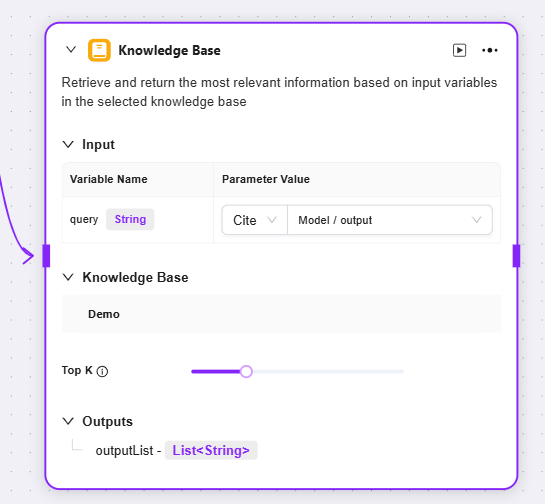
-
インテント認識
-
インテント認識:自然言語処理の重要なステップで、ユーザー入力内容を分析し、実際の意図を特定し、事前設定オプションとマッチング
-
モデル:インテント認識に使用するモデルを選択。モデルがインテント認識能力・効果を決定
-
インテントマッチ:ユーザー意図の説明を事前入力してマッチ基準としたり、他の意図を追加可能。システムはこれに基づきユーザー入力がどのプリセット意図に合致するかを判断
-
高度な設定:システムプロンプト内容の設定が可能で、入力変数を参照してプロンプト効果を最適化できます。また、履歴記憶数を設定し、モデルが過去の会話情報を参照して認識精度を向上させます
-
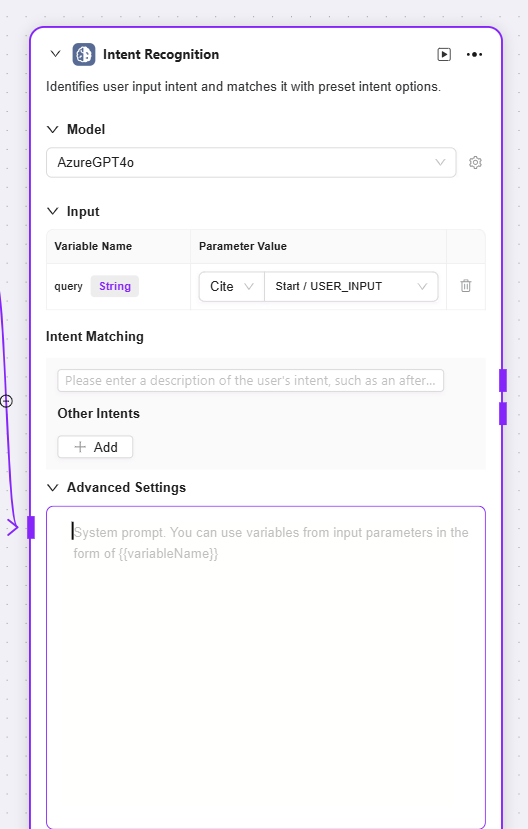
-
テキスト
-
テキスト:主に文字列型変数のフォーマット処理に使用
-
入力:変数名を定義し、参照方式でパラメータ値を取得し、後続テキスト処理用の原始文字列データを提供
-
文字列結合:テキスト編集エリアを提供し、変数名方式で入力変数を参照し、複数文字列の結合などフォーマット処理が可能
-
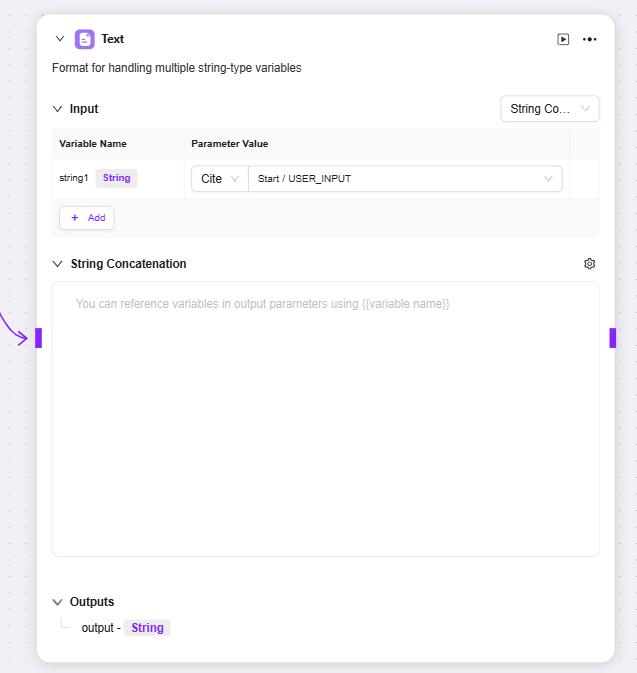
-
ファイル処理
-
ファイル処理:ファイル内容の検索などを行う機能モジュール
-
入力:変数名を定義し、パラメータ値を参照して検索キーワードなどの入力情報を提供し、ファイル内容検索の根拠とします
-
ファイル:処理対象ファイルをこのノードに追加し、検索するファイル範囲を確定
-
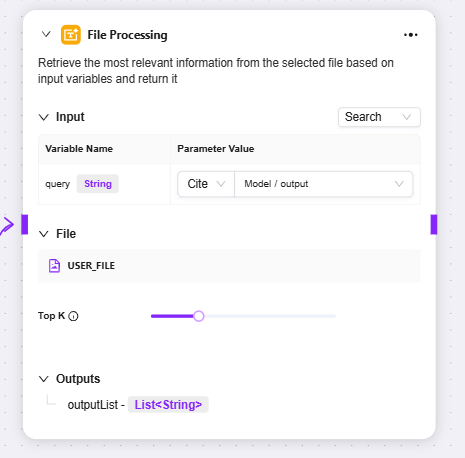
-
データソース
-
データソース:接続するデータソースを選択
-
出力:データソースのデータを出力し、次のノードに渡します。
-

ワークフロー例
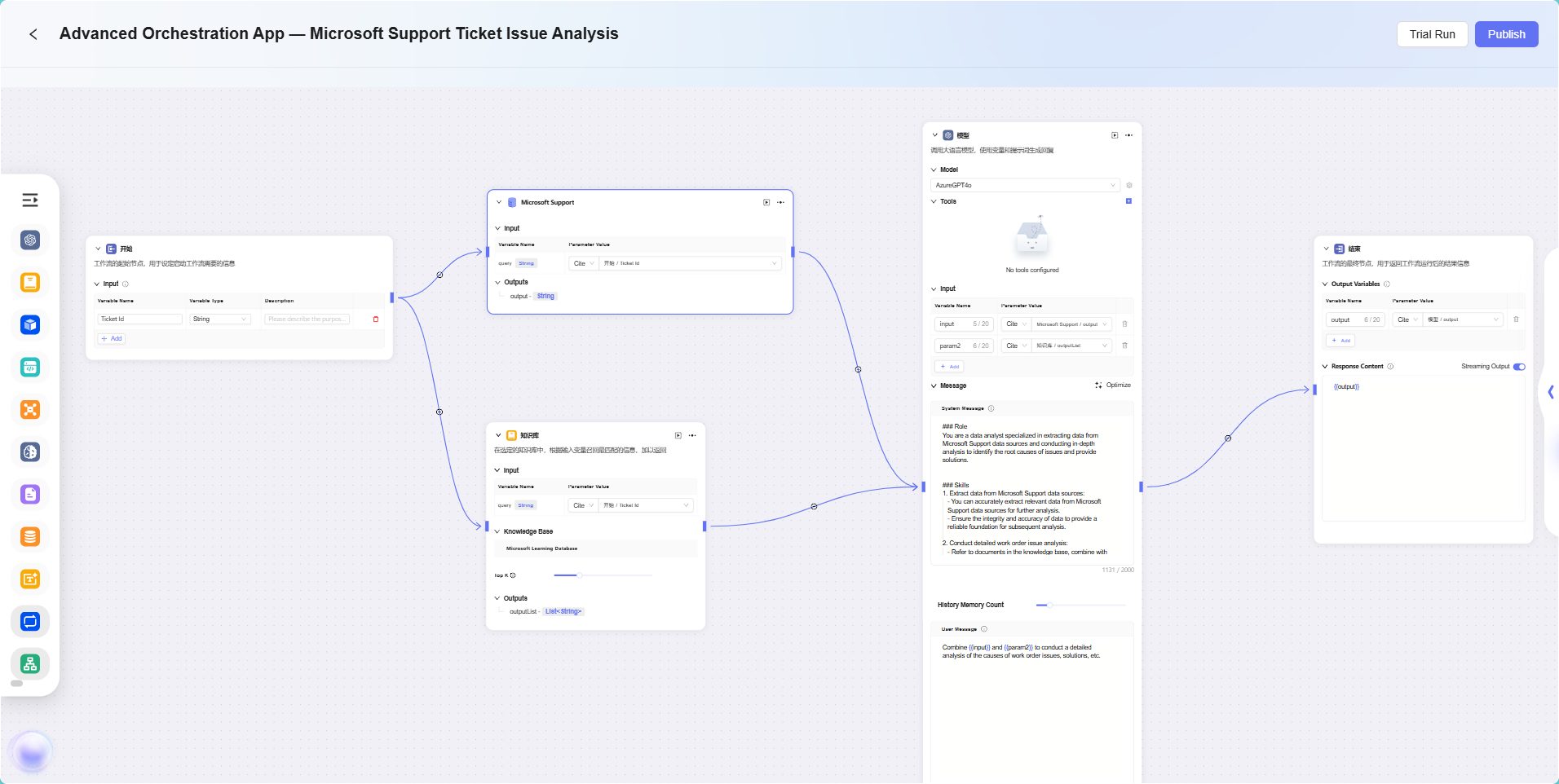
このシナリオでは、ワークフロー機能を使って「Microsoft Support Ticket Issue Analytics」の完全なフローを構築します。具体的な流れは以下の通りです:
-
開始ノード
フローの起点で、システムにデフォルトで含まれています。 -
データソースノード
チケット分析に必要な元データを接続します。 -
ナレッジベースノード
分析参考資料を含むナレッジドキュメントを接続し、AI分析の理論的根拠とします。 -
モデルノード
AIモデルを用いて、データソースとナレッジベース内容を統合し、総合分析を行い、チケット問題分析結果を生成します。 -
終了ノード
フローの終点で、モデルノードの分析結果を出力します。このノードもシステムにデフォルトで含まれています。
データソースノードとナレッジベースノードは並列設定され、モデルノードが両者の情報を集約処理し、出力結果にデータ根拠と理論的裏付けを持たせます。
最終的な効果は以下の通りです:
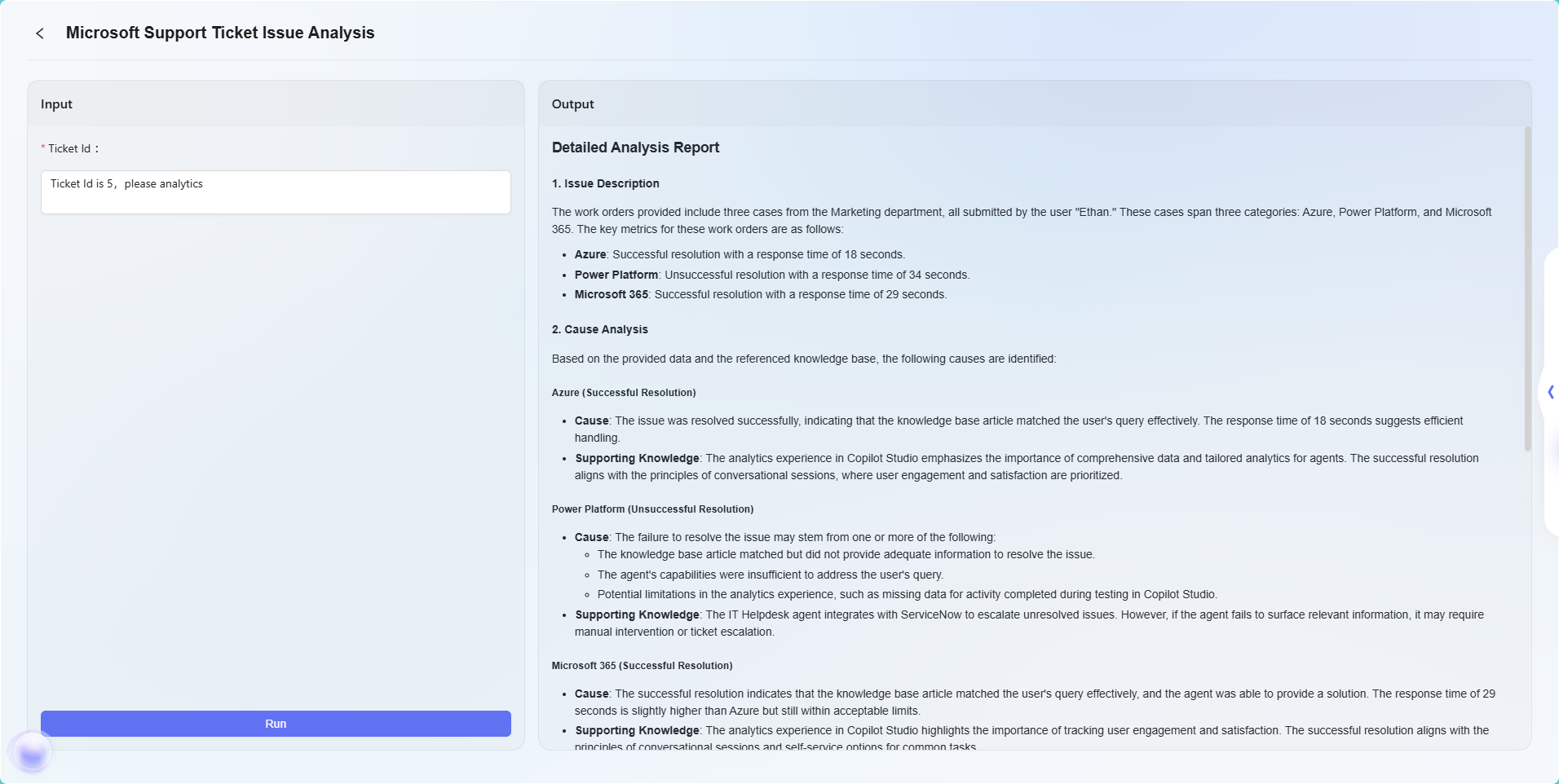
注:本例はアドバンストオーケストレーション機能のシンプルな応用例であり、基本フロー効果のデモ用です。アドバンストオーケストレーションは高い柔軟性と拡張性を持ち、様々なノードタイプを通じて複雑なビジネスロジックやインテリジェント自動化フローを実現でき、幅広い実ビジネスシーンで活用可能です。
シェアコードでインテリジェント体を作成
シェアコード作成はアシスタントのコピーと理解できます。そのコア原理は、既存の成熟したアシスタントから専用シェアコードを生成し、ユーザーはそのコードを取得するだけで新しいアシスタントを素早く作成でき、機能のシームレスなコピーと拡散を実現します。
シェアコードでアシスタントを作成する具体的手順:
- アシスタントの右側の三点をクリックし、「シェア」を選択
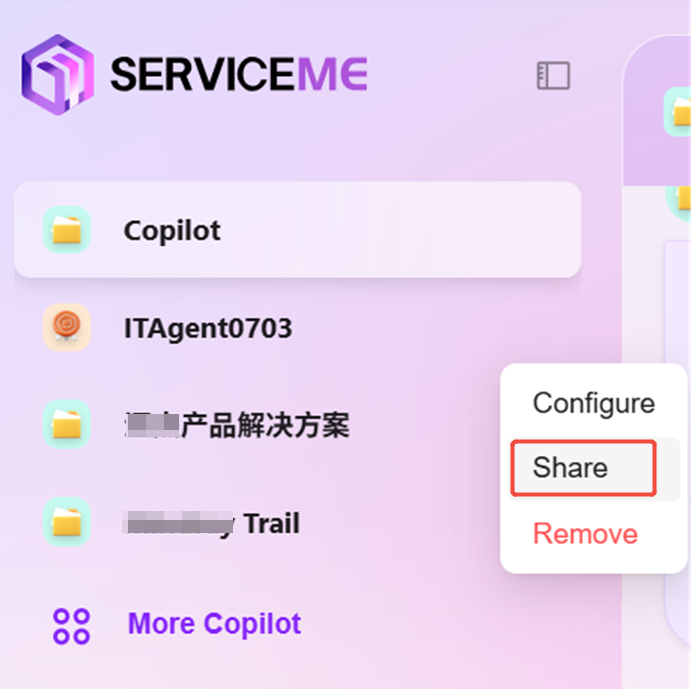
- クリック後、設定コードが生成されるので、コードをコピーして保存
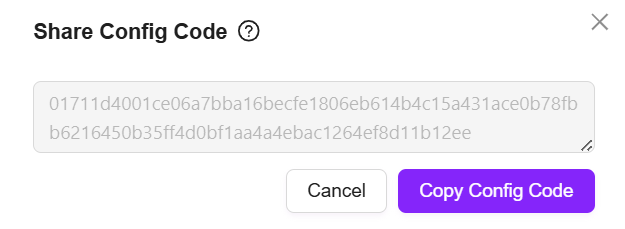
- 「アシスタントを作成」をクリックし、「シェアコード作成」を選択
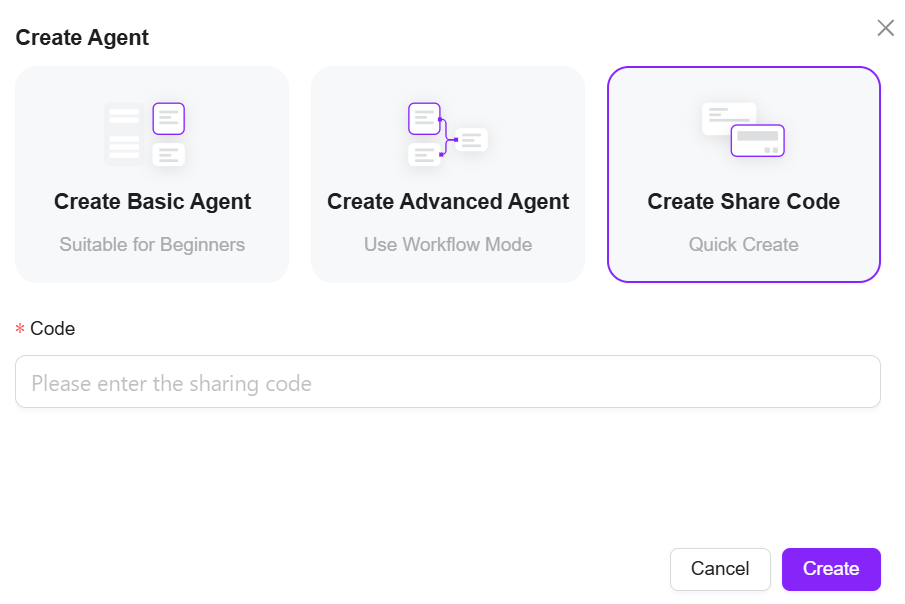
- コピーした設定コードを設定コード欄に貼り付け、「作成」をクリック
アシスタント設定ページで、このシェアコードで作成したアシスタントをシーンに合わせて適宜調整できます。